
OK, der eigene Podcast muss her, das passende Mikrofon ist schon bestellt und die Aufnahme-Software (DAW – Digitale Audio Workstation) ist auch schon startbereit. Aber was muss man bei der Aufnahme vor dem Mikro beachten und wie mischt man die Stimme so ab, dass sie gut und professionell klingt? Es ist nicht trivial, wenn man einen Podcast hochwertig aufnehmen und abmischen möchte. Aber mit diesen Tipps und ein bisschen Übung wird es von mal zu mal leichter – versprochen!
Podcast aufnehmen – Vorbereitung ist die halbe Miete
Inhaltlich solltest Du gut vorbereitet sein, Dein Thema sollte klar und der Text gut strukturiert sein. Oder Du hast Dich für freie Rede oder ein Interview vorbereitet und kannst das Thema angstfrei und flüssig vortragen. Klingt vielleicht banal, aber ein guter Podcast lebt natürlich auch von einem souveränen Podcaster vor dem Mikro. Damit nicht zu viele Schmatzgeräusche oder Verhaspler bei der Aufnahme passieren, hilft es immer vor der Aufnahme genügend zu trinken und sich mit lautem Vorlesen ein bisschen warm zu machen. Auch Sportler machen sich vor dem Wettkampf warm, warum nicht also auch der Podcaster? Ich spreche zum Beispiel immer meine Inhalte vorher ein oder zweimal für mich laut durch.
Magie vor dem Mikro
Hat man das Mikrofon nun angeschlossen, passend und damit nicht zu laut eingepegelt (bei lauter Sprache nicht mehr als -6 – -9 db maximal-Ausschlag), geht es an die Aufnahme. Damit Deine Aufnahme nicht durch störende Plopplaute zerstört wird, solltest Du Dir einen Popp-Schutz für das Mikro zulegen. Bei manchen Mikros ist so einer mitgeliefert, man kann diesen aber natürlich recht günstig erwerben oder auch aus einem Draht-Kleiderbügel und einer Strumpfhose selber bauen. Du brauchst den Popp-Schutz auf jeden Fall um die Plosivlaute beim Sprechen (z.B. P oder K) einzufangen. Speziell diese Laute erzeugen eine starke Luftdruckwelle, die die Membran des Mikros stark aussteuert und zu einem lauten Knall im Signal sorgen kann. Der Poppschutz zwischen Mund und Mikro (am besten auf halbem Weg zwischen beiden) bricht diese Luft-Welle und verhindert Popp-Laute in der Aufnahme.
Abstand halten
Der richtige Abstand zum Mikrofon ist ein entscheidender Faktor für den Grundklang der Stimme. Denn der Nahbesprechungseffekt der meisten Mikrofone lässt die Stimme schnell basslastig und voluminös klingen. Zumindest wenn man beim sprechen sehr nah an das Mikrofon herangeht (ca. 3 – 5 cm Abstand). Man kann diesem Effekt mögen und ganz bewusst wählen, nachträglich ist er aber nicht ganz so einfach zu entfernen oder umgekehrt hinzuzufügen.
Bei einem Abstand von 7 – 10 cm sollte man bei normaler Sprach-Lautstärke völlig auf der richtigen Seite sein um einen angenehmen und natürlichen Klangeindruck der eigenen Stimme aufzunehmen. Nimm hierzu am Anfang ein Maßband oder einfach Deinen Zeigefinger als Richtwert. Wenn Du ungefähr den Abstand entsprechend der Länge Deines Zeigefingers vom Mikro hast, ist alles in Ordnung.
Abstände von mehr als 15 cm lassen die Stimme weiter entfernt klingen. Dies liegt zum einen daran, dass die Stimme leiser aufgenommen wird (was man mit einer Pegelanpassung ja noch ausgleichen könnte). Der Abstand lässt aber auch zu, dass der Raum, in dem man aufnimmt, deutlicher in der Aufnahme zu hören ist. Der Schall der eigenen Stimme verteilt sich halt in alle Richtungen und wird von Wänden, Decke und Fußboden zum Mikro zurückgeworfen. Diese Reflektionen finden sich dann auch in der Aufnahme wieder und sind bei diesem Mikro-Abstand im Verhältnis zur Stimme lauter, als bei geringerem Abstand. Dieser Raumklang lässt sich nur schwer bis gar nicht aus der Aufnahme wieder entfernen, daher sollte man sich gut überlegen, ob man diesen Klangeindruck haben möchte, oder nicht. Solltest Du Dich für nein entscheiden, geh einfach wieder ein wenig näher ans Mikro ran – fertig.
Fix in den Mix
Hat man die Aufnahme mit guter Vorbereitung und passendem Mikro-Abstand gemeistert, geht es an die Nachbearbeitung der Aufnahme. Hier gehe ich in der Regel in drei Schritten und damit mit drei PlugIns vor, und zwar
1. Equalizer, um den Sound ein wenig schöner klingen zu lassen und zu formen
2. Kompressor um die leiseren und lautere Passagen einander anzugleichen, und
3. Limiter, um das Signal auf ein professionelles Lautstärke-Level zu heben.
Equalizer für den Sound
Mit einem Equalizer kann man bestimmte Frequenzbänder anheben oder absenken. So formt man den gewünschten Sound und das Signal wird von störenden oder unanagenehmen Elementen befreit. Klicke gerne mal hier für meine Reihe EQ-Basics, in der ich alles rund um den Equalizer genau erkläre! Ich stelle in der Regel drei verscheidene Frequenzen für eine gute Sprachverständlichkeit ein:
- Mit einem Lowcut-Filter (schneidet die tiefen Frequenzen ab) bei 100 hz bereinige ich das Signal um tieffrequente Anteile, die die Sprache rumpelig oder unverständlich klingen lassen können. Auch Trittschall wird damit wirkungsvoll entfernt.
- Mit einer kleinen Absenkung im Bereich 400 bis 500 hz entfernt man den Frequenzbereich, der das Signal pappig und damit billig klingen lassen kann. Die Absenkung geschieht je nach Geschmack mit 3 – 6 db.
- Eine leichte Anhebung der Präsenzen sorgt für bessere Sprachverständlichkeit und einen klareren Gesamteindruck der Stimme. Ich hebe in der Regel zwischen 4.000 und 5.000 hz um bis zu 4 db an, um dieses Ergebnis zu erzielen.
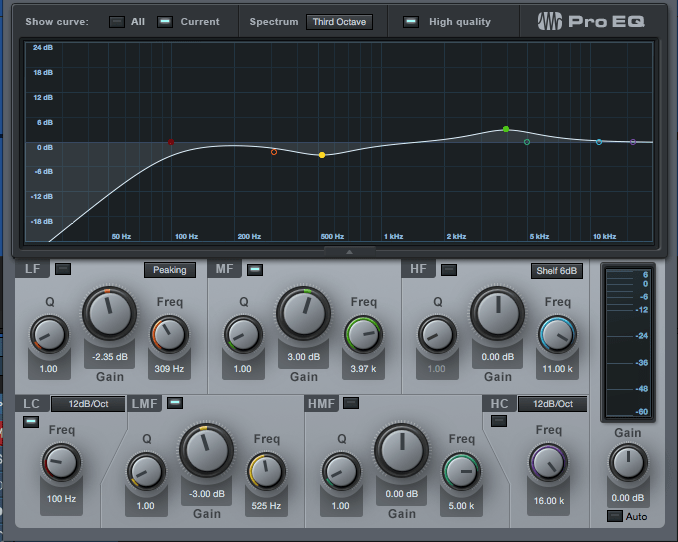
Alles in Allem sollte die Stimme nun schon deutlich klarer und professioneller klingen.
Kompressor für weniger Dynamik
Mit einem Kompressor kann man die Dynamik – also den Abstand zwischen lautester und leisester Stelle im Signal verringern. Dies hat im Podcast den Vorteil, dass leisere Wörter beim Hören nicht so schnell untergehen und überhört werden, lautere auf der anderen Seite nicht schmerzhaft laut sind. Zu diesem Zweck nutze ich in der Regel 2 Kompressoren. Es ginge auch mit einem einzelnen Kompressor, aber der Einsatz von zwei PlugIns sorgt dafür, dass ein einzelner nicht so hart arbeiten muss und das Klangergebnis klingt deutlich entspannter und natürlicher. Wenn Du mehr über Kompressoren wissen möchtest, dann klick doch mal hier und lerne, was alle Knöpfe am Konpressor genau bedeuten und wann und wie man sie einsetzt.
Im ersten Kompressor wähle ich eine Ratio von 4:1, eine mittlere Attack-Zeit von 2 ms und die schnellste Release-Zeit. Damit kommen kleinere Transienten der Stimme durch, nach der Kompression wird das Signal aber sehr schnell wieder auf normalen Level geregelt, was die Stimme sehr konstant im Pegel klingen lässt. Mit den Threshold regele ich nun so weit herunter, bis ungefähr -5 db komprimiert werden. Und genau um diese komprimierten 5 db erhöhe ich das Ausgangssignal mit dem Gain-Regler nun wieder. Das bedeutet die Spitzen werden um 5 db komprimiert, anschließend wird das gesamte Signal (auch die nicht komprimierten leisen Passagen) um 5 db angehoben. So funktioniert ein Kompressor. Er macht die Spitzen leiser, um alles zusammen lauter machen zu können.
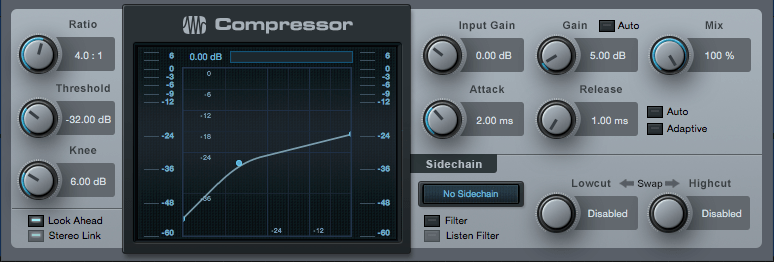
Den zweiten Kompressor lasse ich meistens in der Werkseinstellung (mit selbst regelnder adaptiver Geschwindigkeitsregelung) und regele den Threshold nur so weit herunter, dass dieser Kompressor erneut um -5 db komprimiert. Auch hier ergänze ich die „verlorenen“ 5 db wieder beim Gain. Das Signal wird in der Dynamik um weitere 5 db eingeschränkt und insgesamt um 5 db angehoben. Nun ist es sehr schön gleichmäßig laut.
Limiter für einen professionellen Pegel
Damit das Ganze nun noch auf ein mit dem Radio vergleichbares Gesamtlevel kommt, machen wir die Stimme mit einem Limiter „laut“. Hierbei hilfreich ist, dass der Limiter ab einem gewissen eingestellten Pegel – bei mir meistens – 1 db – alle darüber hinaus gehenden Pegelspitzen rigoros abschneidet. Man macht das Signal also lauter und fährt es damit geradezu gegen diese – 1db – Wand (in Studio One Ceiling genannt) . Daher spricht mann im Fachjargon auch von einem Brickwall-Limiter, einem Steinwand-Begrenzer!
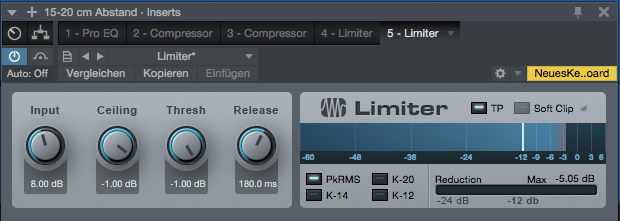
Den Input dreht man so lange auf, bis der mittlere RMS-Pegel im Bereich -12 db zu finden ist. Bei Studio One wird dieser zum Beispiel durch zwei weiße Striche signalisiert, die oberhalb des Peak-Meters (lange blaue Balken) zu finden sind und den mittleren Pegel anzeigen. Wenn Du Dich für das „Warum?“ an dieser Stelle interessierst, empfehle ich Dir hier mal genauer nachzulesen.
Wichtig ist, was hinten rauskommt
Am Ende dieser Kette aus Aufnahme und Bearbeitung steht eine professionell klingende, gleichmäßige Stimme mit professioneller Lautheit. Und für nichts weniger treten wir doch an, oder? Wenn ich Dir hiermit helfen konnte, dann schreib Doch Deinen Podcast mal in die Kommentare unter dieses Video und ich freue mich in Deine Werke reinzuhören und die Früchte Deiner harten Arbeit zu bewundern.
Du kannst Dir die Studio One Session übrigens unter diesem Link herunter laden, entpacken und alle Einstellungen (ab Studio One 3.5) auch noch mal selber nachvollziehen und damit rumspielen. Einfach hier klicken und runterladen. Viel Spaß damit!