
Einen Equalizer für eine gelungene oder misslungene Aufnahme in einem Podcast, bei Gesangs- oder Rap-Aufnahmen einzustellen, ist kein Hexenwerk. Natürlich wirkt ein ausgewachsener Equalizer wie beispielsweise der kostenlose und ausnahmslos zu empfehlende TDR Nova (hier gratis downloaden) erst mal überwältigend. So viele Einstellmöglichkeiten, Knöpfe und keine Idee, wo man anfangen soll. Ich zeige Dir in diesem Artikel, wie Du ganz gezielt an die Bearbeitung Deiner Stimme mit einem Equalizer herangehen und Deine Aufnahme ganz einfach im Klang optimieren kannst.
Equalizer einstellen für Podcast, Gesang und RAP
Der TDR Nova bietet alles, was ein moderner Equalizer als Plugin bieten muss, hat darüber hinaus aber noch einige Profi-Features mit an Bord, die man anderswo teuer bezahlen muss. Wenn Du alles über das Einstellen von Equalizern und ihre verschiedenen Filtertypen lernen möchtest, findest Du hier eine ausführliche Artikelreihe, in der ich Dir alles bis ins kleinste Detail erkläre.
Um Deine Aufnahme nun gezielt zu optimieren, gilt es erst einmal herauszufinden, welches Problem in der Aufnahme vorliegt. Dabei helfen Beschreibungen und Adjektive, den genauen Klang zu benennen. Etwa: Die Stimme klingt dünn, dumpf, fett, basslastig, zu spitz, etc. . Für all diese Probleme gibt es ein Hilfsmittel im Equalizer, mit dem man die Schwächen im Signal zumindest abmildern, oftmals aber sogar gänzlich beheben kann.
Stimme optimieren mit 3 einfachen EQ-Einstellungen
Um hier aber nicht zu sehr in Expertenwissen abzudriften, konzentrieren wir uns in diesem Artikel auf drei sehr Einsteiger-freundliche Filtertypen, nämlich den Low-Shelf, den High-Shelf und den Glocken- oder englisch Bell-Filter. Alle drei haben unterschiedliche Bearbeitungsansätze, weswegen wir uns diese jetzt mal etwas genauer anschauen und ich Dir parallel erkläre, welches Problem Du damit beheben kannst.
Low-Shelf für die tiefen Frequenzen
Ein Shelf-Filter wird auf Deutsch auch Kuhschwanzfilter genannt und wenn man mit so einem Shelf-Filter mal einen Frequenzbereich anhebt oder absenkt, erkennt man auch sofort optisch die Analogie, die Du auch auf dem folgenden Bild gut nachvollziehen kannst:
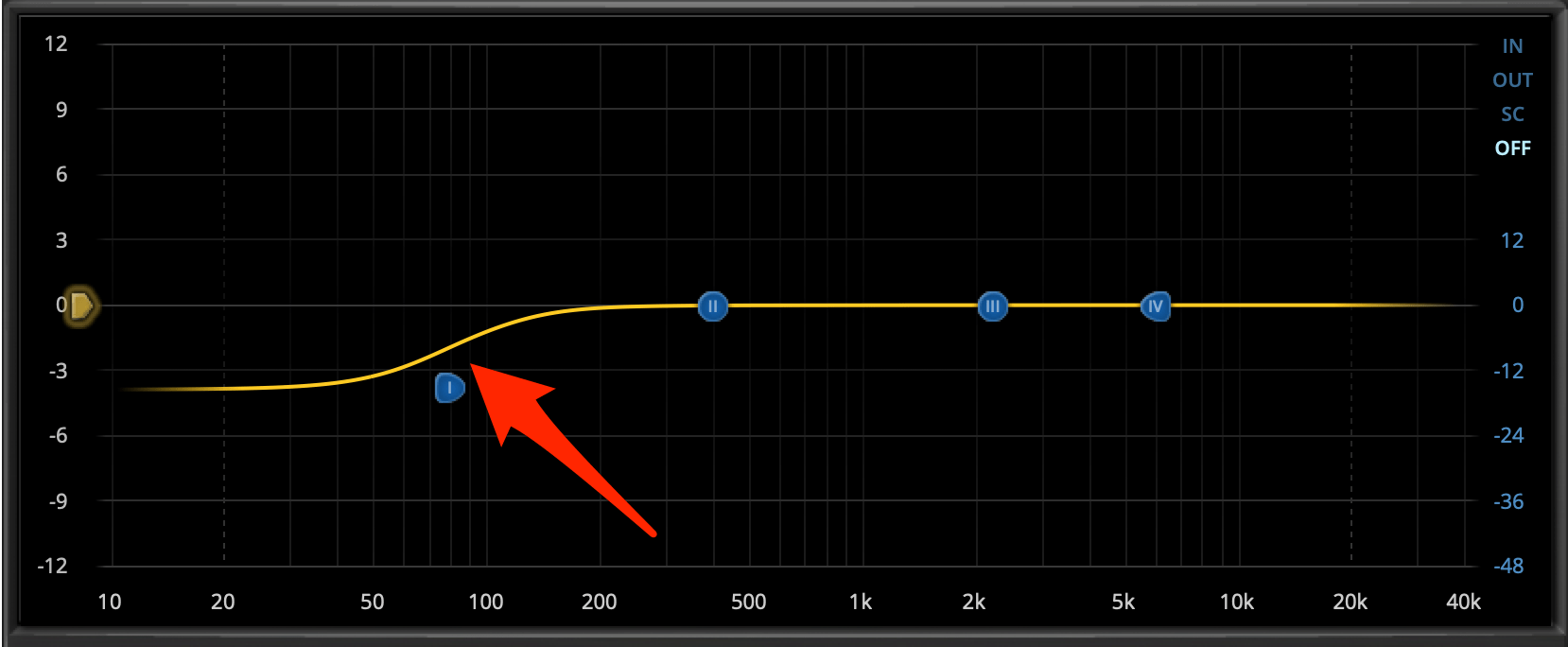
Mit einem Shelf-Filter kann man also ab einer gewissen Grenzfrequenz alle darunter (Low-Shelf) oder darüber (High-Shelf) liegenden Frequenzen anheben oder absenken. Du bekommst damit ein Hilfsmittel um einen sehr weitreichenden Frequenzbereich bearbeiten und erzielst dabei meist ein sehr natürlich klingendes Klangbild.
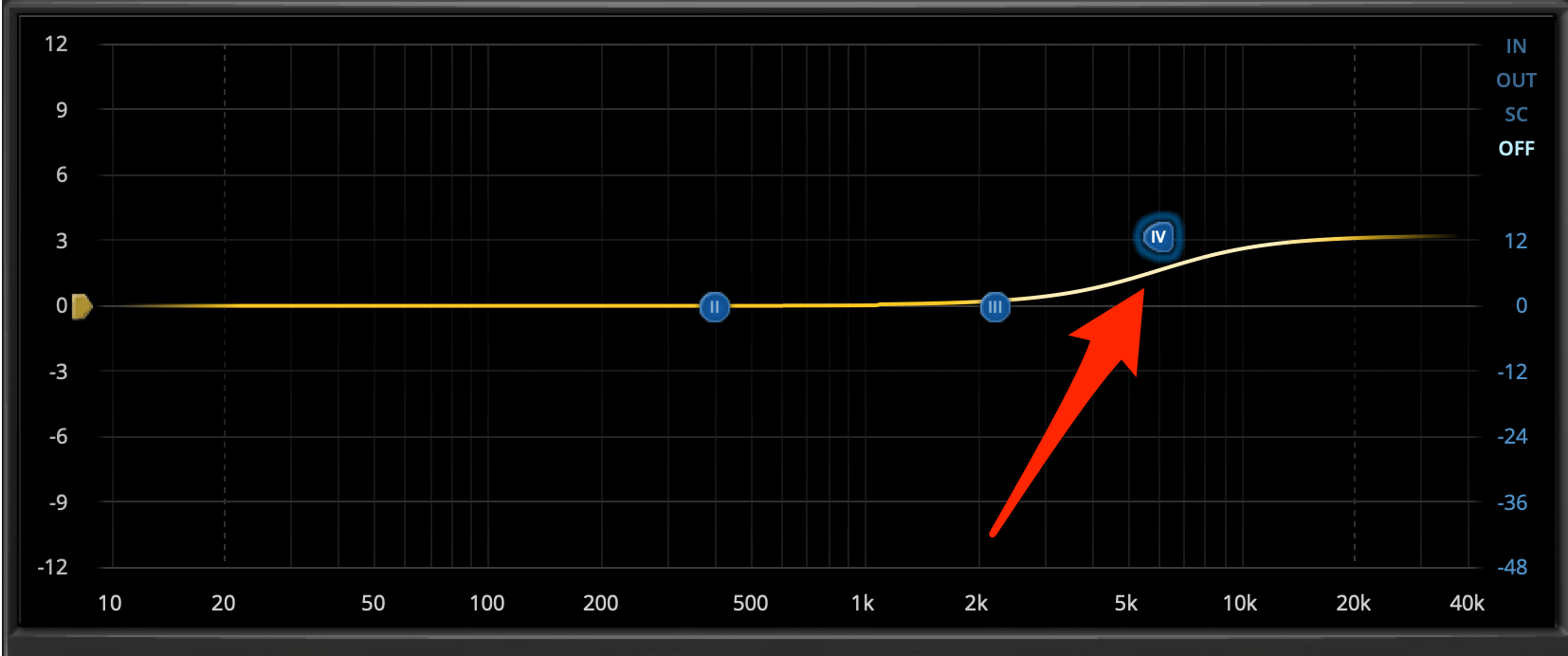
High-Shelf für die hohen Frequenzen
Wie oben schon geschrieben ist auch der high-Shelf ein breitbandiger Filter, der im Gegensatz zum Low-Shelf-FIlter für den höheren bis hohen Frequenzbereich zuständig ist. Auch hier wird das Klangbild sehr breitbandig und damit auch recht natürlich beeinflusst und Du kannst mit dem High-Shelf zu spitz klingende Signale abmildern oder zu dumpf klingende Aufnahmen aufhellen und verständlicher machen.
Bell-Filter für den gezielten EQ-Einsatz
Der Bell-Filter (zu deutsch Glocken-Filter) verdankt seinem Namen genau wie der Kuhschwanzfilter dem Aussehen des von ihm beeinflussten Frequenzbereiches.
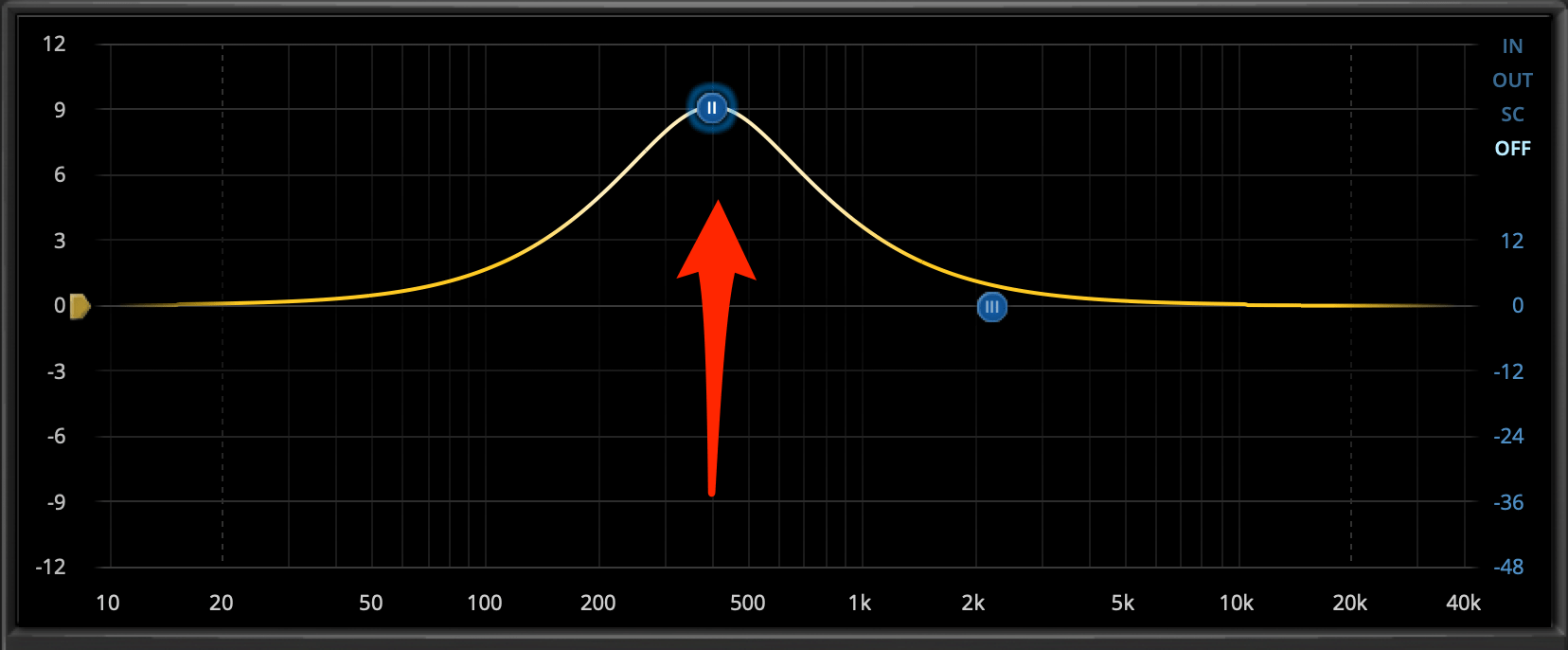
Mit dem Bell-FIlter kann man rund um eine Kernfrequenz entweder sehr breitbandig oder sehr schmalbandig anheben oder absenken. Dabei kann man sowohl sehr breitbandig Einfluss auf das Signal nehmen, aber auch gezielt störende Resonanz-Frequenzen absenken, ohne das restliche Klangmaterial zu beeinflussen oder sogar zu beschädigen. Der Bell-Filter ist also ein sehr flexibles Werkzeug. Wir bleiben in diesem Artikel eher bei einem breitbandigeren Einsatz, da das gekonnte Herausfiltern von Resonanz-Frequenzen etwas mehr Erfahrung benötigt. Wir bleiben hier aber zunächst einsteigerfreundlich und beheben nun mal zwei übliche Probleme mit Aufnahmen von Stimmen.
Die Stimme klingt zu dumpf und wummerig
Wenn eine Stimme in der Aufnahme dumpf und wummerig klingt, kann das an zwei Dingen liegen haben: Zum einen hat das aufgenommene Signal einfach einen zu hohen Anteil an tiefen Frequenzen unterhalb 200 – 250 hz, oder es hat zu wenig Anteile in den höheren Registern ab 5 khz aufwärts. Meistens ist es aber beides! Hier helfen die beiden Shelf-Filter wirklich schon gut aus. Mit dem Low-Shelf kann man bei einer Grenzfrequenz im Bereich 200 – 250 hz schön breitbandig absenken, bis es nicht mehr so wummerig klingt.
Um anschließend noch mehr Brillianz und bessere Verständlichkeit der Stimme zu erzielen, kannst Du mit dem High-Shelf noch oberhalb von 5 khz oder auch höher anheben, bis es angenehm, aber nicht zu spitz klingt. Bedenke aber, dass Du bei zu starkem Einsatz des High-Shellf auch die S-Laute in der Stimme etwas überbetonen kannst. Der vorsichtige Einsatz beider Filter ist also angeraten.
Die Stimme klingt zu dünn und grell
Klingt Deine Stimme zu dünn und zu grell, liegt das zum einen an einem Übermaß an hohen Frequenzen, sowie an zu wenig tieffrequentem Material. Auch hier können Low-Shelf und High-Shelf schon mal gut ausbessern. Mit dem Low-Shelf kannst Du unterhalb von 200 bis 250 hz anheben, bis sich eine angenehme Wärme im Signal einstellt. Hier vorsichtig sein und lieber etwas weniger als etwas mehr nehmen, damit man ein möglicherweise vorhandenes „Grund-Rumpeln“ wie zum Beispiel Trittschall nicht übermäßig betont.
Zum anderen kannst Du mit dem High-Shelf die unangenehmen Höhen ab 6 – 8 khz aufwärts so weit absenken, bis es nicht mehr unangenehm klingt. Auch hier bitte vorsichtig und maximal 3-4 db absenken, da es sonst schnell wieder zu dumpf klingen kann. Wenn DU Dir nicht sicher bist, kannst Du auch immer mal wider den Equalizer auf Bypass stellen um zu vergleichen, wie das Signal vor und nach der Bearbeitung klingt. Das ist oft zielführender als langes, unsicheres „Knöpfe-Drehen“, da Du im direkten Vergleich viel besser den Unterschied hören kannst.
Die Stimme klingt zu nasal und unnatürlich
Ist Deine Stimme zu nasal und kllingt, als ob sie in einer Pappschachtel aufgenommen wurde, ist dies meist dem Frequenzbereich rund um 500 hz geschuldet. Mit einem Bell-FIlter kannst Du hier schnell und präzise eingreifen und nur den Bereich rund um z.B. 500 hz absenken und damit die Stimm-Aufnahme deutlich klarer zu gestalten. Zu diesem Frequenzbereich habe ich auch schon mal ausführlicher geschrieben, was Du auch hier nachlesen kannst: Große Wirkung im Mix: Alles klingt besser ohne 400 hz
Aber auch andere Bereiche können überbetont oder unterrepräsentiert sein. Ist die Stimme zu quäkig, liegt das an einer Überbetonung bei 1.000 bis 2.000 hz. Ist sie nicht verständlich genug, kann eine Anhebung mit dem Bell-Filter (Q-Faktor 1) im selben Frequenzbereich dafür sorgen, dass die Stimme besser verständlich ist oder sich in einem Musik–Mix besser durchsetzt. Die vielbeschworene Sprachverständlichkeit kann hier gezielt unterstützt werden.
Fazit
Oft benötigt eine Stimm-Aufnahme eine Kombination aus den verschiedenen Filter-Typen. Wenn Du Dich aber immer am Problem der jeweiligen Aufnahme entlang arbeitest, kannst Du Deine Stimme schnell und zielgerichtet optimieren. Zu dumpf? Bass mit Low-Shelf absenken. Zu quäkig? Mitten absenken. Zu wenig brillant? Höhen mit High-Shelf anheben. Und so weiter. Bearbeite Deine Stimme mit diesen Hilfsmitteln, bis Dich nichts mehr daran stört und schalte vor allem immer mal wieder den EQ auf Bypass, um zu überprüfen, ob die letzte Einstellung dem Signal hilft oder eher das Gegenteil bewirkt. Viel Spaß und viel Erfolg dabei!